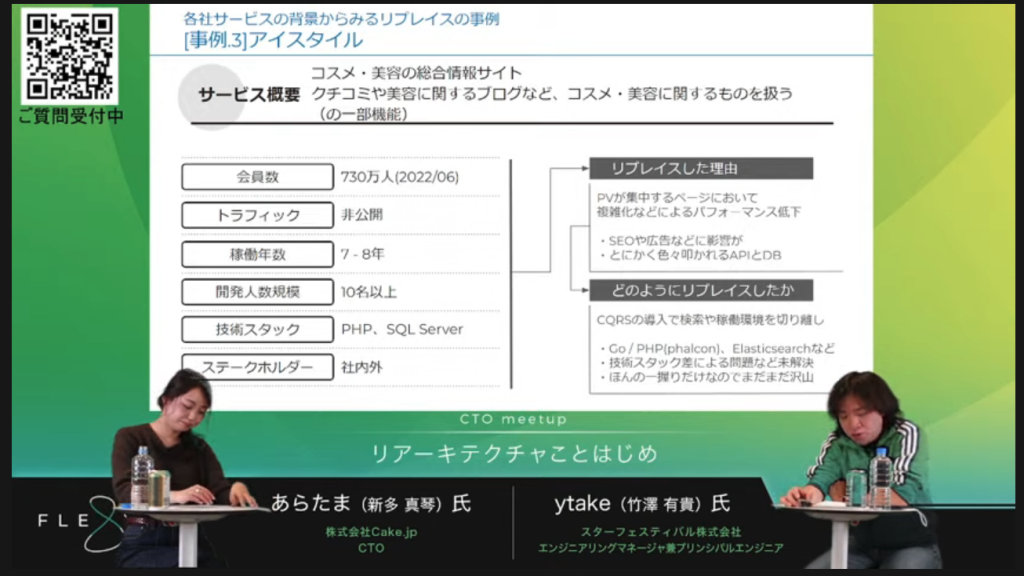
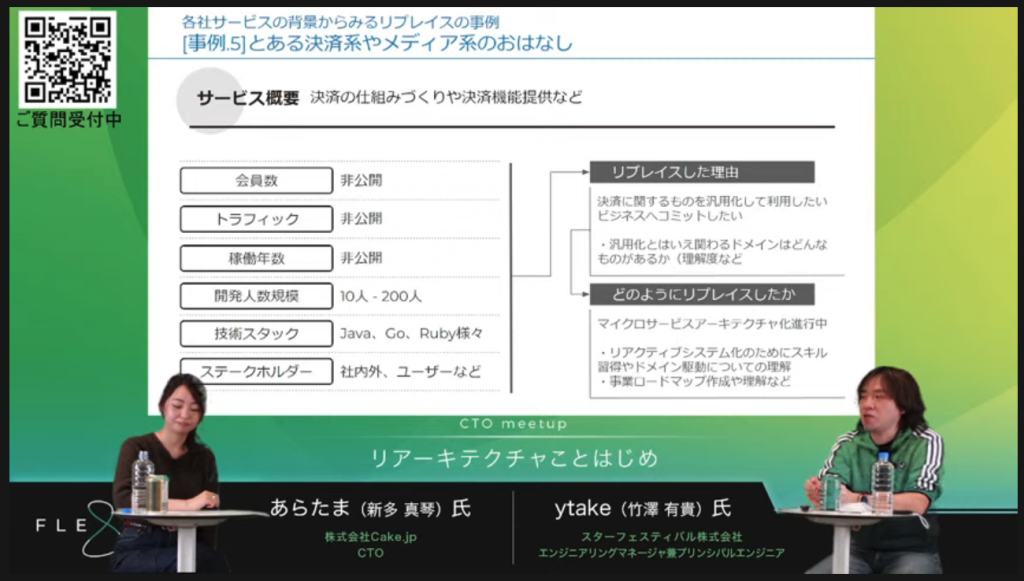
プログラミングにおけるより良い選択とは〜『ソフトウェア設計のトレードオフと誤り』から紐解く設計方法〜
https://findy.connpass.com/event/300004/
に参加してきたので、聴講メモです。
イントロダクション:書籍『ソフトウェア設計のトレードオフと誤り』について 渋川さん
資料
本の概要紹介
全部で13章あり
- プログラミングな話
- 分散システム系な話(分散システムに詳しい人が書いた部分)
- 日付と時刻の話(この章は結構他と毛色が違う)
のようなことが書いてある
どんな本?
プログラムは書いた通りにもちろん動くが、メンテナンス性や性能や拡張性などの部分は考える必要がある。
様々な業務経験から議論が深掘りされているため、渋川さん自身も発見が多かった。
逆にどんな本ではない?
- 手っ取り早くコードを読みやすくするとかではない
- リーダブルコードみたいな感じではない
- ある程度コードを読みやすくする心得みたいなのは知ってる前提の、初心者を突破した人レベルが対象
- 正解を求める向け人ではない
- クリーンアーキテクチャの本とかでもそうだけど、「こうすればいい」を求めてる人向けではない
- おそらく正解を求める思想の人は、現実ではそんなことはないと感じると思う
- 現在多く使われているフレームワークを網羅しているわけではない
トレードオフとは?
トレードオフは判断基準によって変わるし、
トレードオフから決断をするときには、更に別な基準が入ってきたりする。
トレードオフは面白い
- 採用しなかったアーキテクチャも残したらいいのではないか。
- 他案でどんなものがあったのか。
- 状況が変わったら採用しなかった他案が参考になるのではないか。
- 初心者が読んだら参考にもなるのではないか。
パネルディスカッション「渋川さん・松岡さんならどちらを選ぶ?」
トレードオフがある複数の選択肢のうち、お二人なら何を選ぶのかをお話いただきます!
コードの重複vsコードの柔軟性
渋川さん
重複は気にしない
DRYの法則でも、3回以上重複するなら改善しようとなっていて、逆に3回までなら良いかなと思う。
最初から重複を排除しようとすると必要以上に複雑になったりもする。
松岡さん
テーマが 〇〇 vs 〇〇 となっているが、スタンスは違うものではないと思う。
重複というより、知識や責務で分けるのが良いと思う。
たまたま同じプロパティだったとしても、
たまたま同じだったユースケースが違うものだったりもする。
それを一緒の扱うようにしちゃうと難しくなる。
クリーンアーキテクチャは難しくて認知負荷も高いが、
社内でも責務を分けるのが大切というのを繰り返し発信するようにしている。
渋川さん
フレームワークによっては、
バリデーションはここに書くと決まってると、自然と責務を分けられるようになったりもする。
Q1
コードの重複について、各クラスに分散してしまっているものはどのように検知していらっしゃいますか?
静的解析で賄える部分もありますが、気付かぬうちに重複が増えてしまっていたケースのコントロールに苦戦してます。。
A1
松岡さん
自動検知はそんなにできなそうとは思っている。
自分たちはパッケージに分けるとかのルールがあって、リファクタをしやすくするようにしている。
みつけたら改善するというようにしている
渋川さん
そもそも重複を排除したほうがいいのかを考えるのもいいかもしれない。
例外 vs 他のエラーハンドリングパターン
渋川さん
このフレームワークや言語ならこういうやり方だよねというのがあるので
それから離れないほうがいいかもしれない。
例えば関数型を学んだからモナド使ってみようかなみたいなのは
他の人からしたらノイズになったりする。
例外の仕方というよりは、例外は最終的に誰が処理するのかを考えたほうがいいかもしれない。
ユーザーにどう対応するのか、社内の誰かがどう例外に対応するのか等を考えて
そこから、最終的にどうするために例外こうしようということを考えたほうがいいかも。
松岡さん
渋川さんに同意。
言語によっては、例外の投げ方をどうするかとかの議論はあると思う。
TypeScript や Kotlin などで、例外を投げるのかエラーを return するのかとか
そういう話が出てくるときはある。
Q2
個別具体の例外ルールが積み重なって負債のようになっており、別管理になっているのですが、例外処理を作りすぎない方がいいなどの目安はありますか?
A2
渋川さん
例外処理を作りすぎというのは、例外の型を作りすぎという意味だとして、
最終的に例外を処理する人が運営の人なのかサポートの人なのかとかだと思うが
その人たちが対応できるように、リストを作っておくといいのかなと思う。
例外はシステム外で対応するという話なので。
流行を追いかけ続けること vs コードのメンテナンスコスト
渋川さん
仕事で選ぶことが多いのは、ある程度歴史がある言語やフレームワーク。
Rust ももう10年くらいたってるので、安心して使えるかもしれない。
ただ、フロントエンドは最新を追いかけてる。
フロントエンドの新しいものは革新的で自分たちの利益になると大きい。
松岡さん
渋川さんに同意。
追いかけるというより、学んでいくといいことがあると思っていて
新しいトレンドを知っていくと、よりよい書き方とかが学べて今後取り込んでいく選択肢になるので
学んでいくのが良いと思う。
Q3
最近の言語は例外がないものが増えてきているのですが、例外を使うメリットは何でしょうか。個人的には解析性やマイクロサービス化が進むことでデメリットのほうが多い気がしています
A3
渋川さん
例外が発生したら一箇所で処理できるのでいいというのが、例外が発明されたときはあったかもしれない。
ただ、いろいろ意見があって例外は例外で扱いづらいところとかはあるかも。
松岡さん
さっきの Go の panic の話もあったが、本当にシステムとしてどうしようもないみたいなときは
例外を投げてまとめて処理できるともしかしたら良いのかも知れない。
そうじゃないときは分岐させてみたいな使い分けができるといいかもしれない。
Q4
現在プロダクトに残っている例外処理のいくつかが実装当時の意思決定が残っておらず、惰性でそのままなのですが、改善すべきでしょうか?
当時の思想がわからない例外処理の取り扱いのご意見を伺いたいです
A4
状況によるかもしれない。
握り潰しているのかもしれないが、それで困っているなら改善したほうがいいかもしれない。
Q5
コードのメンテナンスにかかるコストを計測されていたりしますか?
属人化されており、現在は良いのですがその方が異動等でいなくなった場合の対処法に悩んでおります。
A5
松岡さん
ここがこのくらいぐちゃぐちゃだと、こう困るよというのを言語化するために計測するとかのほうがいいかもしれない。
渋川さん
コストを計算したものを一概に判断はできないかも。
AさんがやるのとBさんがやるのでかかる時間も違うので。
Q6
昨今のLLMの隆盛から開発に取り入れるべきか悩んでいるのですが、流行に乗ってどんどん取り入れるべきなのでしょうか?
生産性向上の反面、これまでの標準から外れることやメンテナンスコストに見合うか否かの判断はどうお考えでしょうか?
A6
松岡さん
入れるというのも、開発プロセスに入れるのか、プロダクトに入れるのかで大分話が変わる。
プロダクトには合う合わないがあるので、そこを考えるしかないかも。
開発プロセスは、copilot 入れたらアシストしてくれるので、いれてみたらいいんじゃないかなと思う。
渋川さん
プロセスだという前提で、
生成されるコードもレビューをしたりするので、全部おまかせで生成にはならないとおもう。
Javaでも歴史の中で流行りの書き方とかがあって、古い書き方を生成されたりもするので、そういうのは改善するし。
生成が得意なものもあったりするので、熟したものを使うとかはあるかもしれない。
Q7
少人数で開発していた初期フェーズから組織がグロースしていく中で、チーム毎に開発が多様化してコードの重複や書き方が複雑化していくと思っています。
保守コストの高さを許容してでも共通ロジック化を進めるべきタイミングはいつ頃と考えられてますか?
渋川さん
先手先手でやるしかないと思う。
松岡さん
共通化の責務を誰が見るのかが大事かも。
全員自分のコードしかみてないとかだと良くなくて、横串で誰がが責務を持ちますというのがあると良いかも。
クロージング
渋川さん
実は、会社のテックブログを年間200記事近く投稿とかしてます
よかったら見てね
Future Tech Blog好評配信中
https://future-architect.github.io/
松岡さん
社内で、毎週絶対記事出す、更新が止まったらそこで終了というイベントをしている(現在13週目)
https://zenn.dev/p/loglass
質問箱もやってます
https://querie.me/user/little_hand_s?ts=1701151680883
togetter まとめ
https://togetter.com/li/2267188
参加しての感想
渋川さんがおっしゃっていた、採用しなかった設計もドキュメントに残すと良いのではないかというのは自分もそう思っていて基本的に残すようにしている。
採用しなかった設計というよりは、「なぜいまこの設計や選択肢を取ったのか」を記載するようにしていて、その意思決定の材料として「背景として他にこういう選択肢もあったが、こういう比較検討をした結果こちらを採用した」を残すようにしている。
理由は渋川さんがおっしゃっている通りで、将来状況が変わったときに「既存のようになっている理由がそれであるのなら、こういう変更をするのは問題ないだろう」という、将来の変更の助けになるためにしている。
また、イベント開催前にパネルディスカッションテーマを見ていたときに、「vs と書いてあるが、これはどちらが良い悪いとか、排反しているとかではなく、ソフトウェアを変更を容易にするための手段であって、目指してるところは同じの認識」と思っていたが、松岡さんも近しいことをおっしゃっていたように思えて、自分の認識が違ってなさそうで安心した。(イベントのタイトルが「トレードオフと誤り」なので、あえてのディスカッションテーマだったのかも)
「例外はシステム外で対応するという話なので、最終的に誰がどう処理するのかを考えるのが大事」という点で、確かに自分も例外を投げるときは、その後の人での対応はどうするを考えているが、言われてみて「たしかに」と改めて思うところだった。
他の参加者の方からの質問で、静的解析ツールや LLM を使うケースもよくあったなぁと感じた。
自分はその辺りにはまだ疎いので、勉強していきたい。
今回テーマになってる本の存在は知ってたのだけど読んでないので、読みたくなった
「ソフトウェア設計のトレードオフと誤り―プログラミングの際により良い選択をするには」https://www.oreilly.co.jp/books/9784814400317/